Spark Performance Optimization Series: #1. Skew
4.5 (723) In stock

In Spark cluster data is typically read in as 128 MB partitions which ensures even distribution of data. However, as the data is transformed (e.g. aggregated), it is possible to have significantly…

Spark's Skew Problem —Does It Impact Performance ?, by Aditya Sahu, Curious Data Catalog

Monitoring Apache Spark – We're building a better Spark UI - KDnuggets
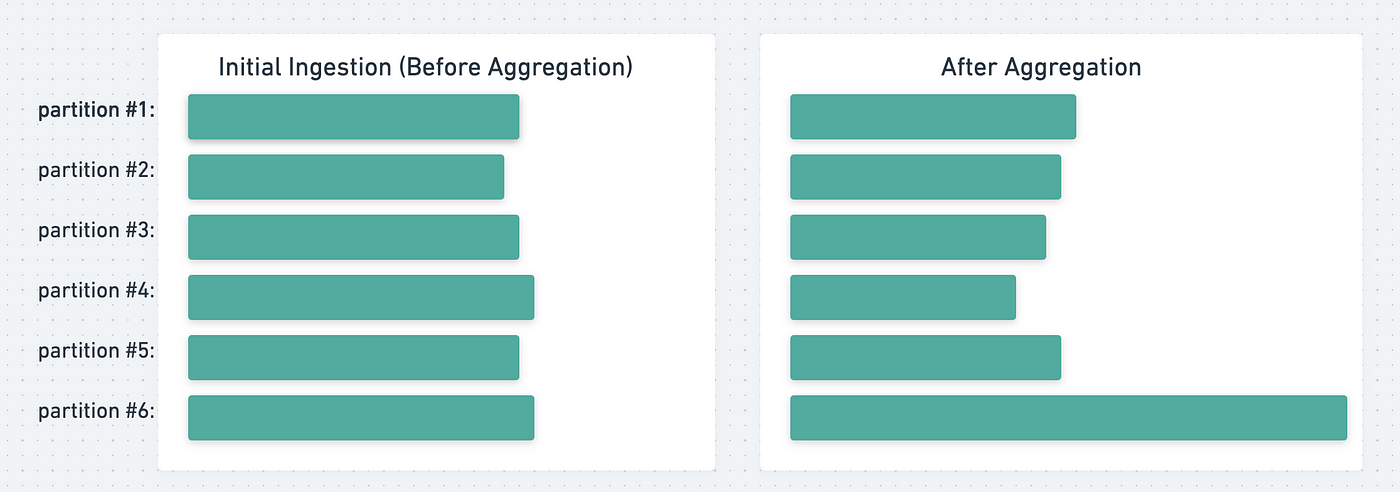
Spark's Skew Problem —Does It Impact Performance ?, by Aditya Sahu, Curious Data Catalog

Spark Performance Optimization Series: #2. Spill, by Himansu Sekhar, road to data engineering

List: Reading list, Curated by mohit chaurasia

How to Optimize Your Apache Spark Application with Partitions - Salesforce Engineering Blog

Apache Spark 3.0 and skew join optimization in the Adaptive Query Execution

High Performance Spark: Best Practices for Scaling and Optimizing Apache Spark 1, Karau, Holden, Warren, Rachel, eBook

How to Optimize Your Apache Spark Application with Partitions - Salesforce Engineering Blog

Skewed Join Optimization in Spark

How to Optimize Spark Applications for Performance using Sparklens
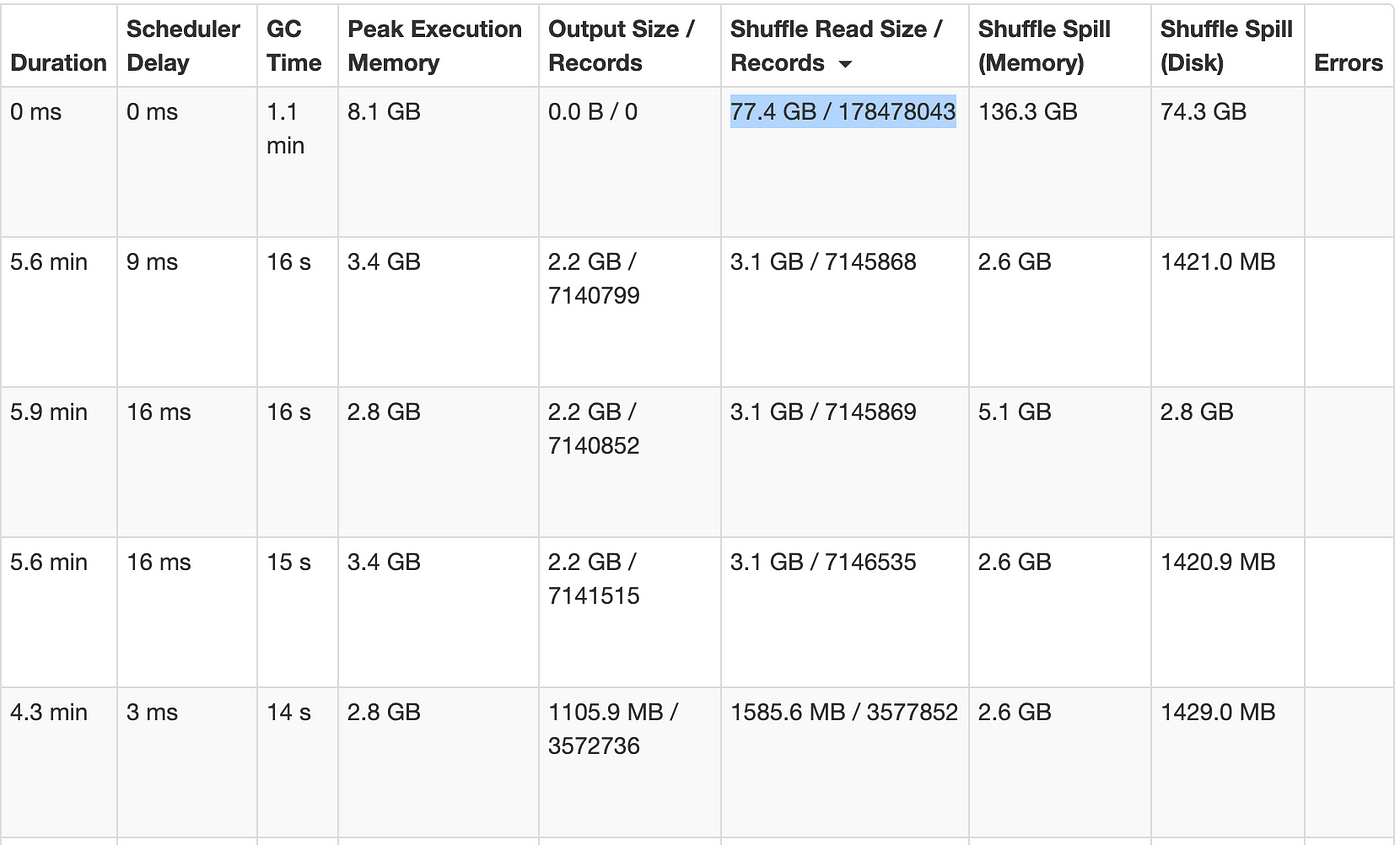
Handling Data Skew in Apache Spark, by Dima Statz

Stream Data from Kinesis to Databricks with Pyspark, by Himansu Sekhar, road to data engineering
yall out here taking personality quizzes bruh i just wanna know
Felix Thießen on X: @NoDunksInc @jeskeets @snark_tank @LeighEllis
 Men's L/S Stretch Cotton Henley - Hydrow Apparel Store
Men's L/S Stretch Cotton Henley - Hydrow Apparel Store Sanuk Yoga Sandy Metallic Flip-Flop Sandals Strappy 11 Women's
Sanuk Yoga Sandy Metallic Flip-Flop Sandals Strappy 11 Women's 10 Simple Ways To Get Six Pack Abs For Women
10 Simple Ways To Get Six Pack Abs For Women bebiullo Women Bling Sequin Cami Vest Top Y2k Sexy Spaghetti Strap Tank Top Backless Rhinestone Camisole Night Club Partywear (Silver, S) at Women's Clothing store
bebiullo Women Bling Sequin Cami Vest Top Y2k Sexy Spaghetti Strap Tank Top Backless Rhinestone Camisole Night Club Partywear (Silver, S) at Women's Clothing store black tank top and white turtleneck blue cargo pants
black tank top and white turtleneck blue cargo pants Lolmot Sexy Ladies Bra Without Steel Rings Vest Bra Plus Size Breathable Solid Lingerie Underwire Nursing Bras
Lolmot Sexy Ladies Bra Without Steel Rings Vest Bra Plus Size Breathable Solid Lingerie Underwire Nursing Bras