Complete Guide On Fine-Tuning LLMs using RLHF
4.6 (501) In stock
Fine-tuning LLMs can help building custom, task specific and expert models. Read this blog to know methods, steps and process to perform fine tuning using RLHF
In discussions about why ChatGPT has captured our fascination, two common themes emerge:
1. Scale: Increasing data and computational resources.
2. User Experience (UX): Transitioning from prompt-based interactions to more natural chat interfaces.
However, there's an aspect often overlooked – the remarkable technical innovation behind the success of models like ChatGPT. One particularly ingenious concept is Reinforcement Learning from Human Feedback (RLHF), which combines reinforcement learni
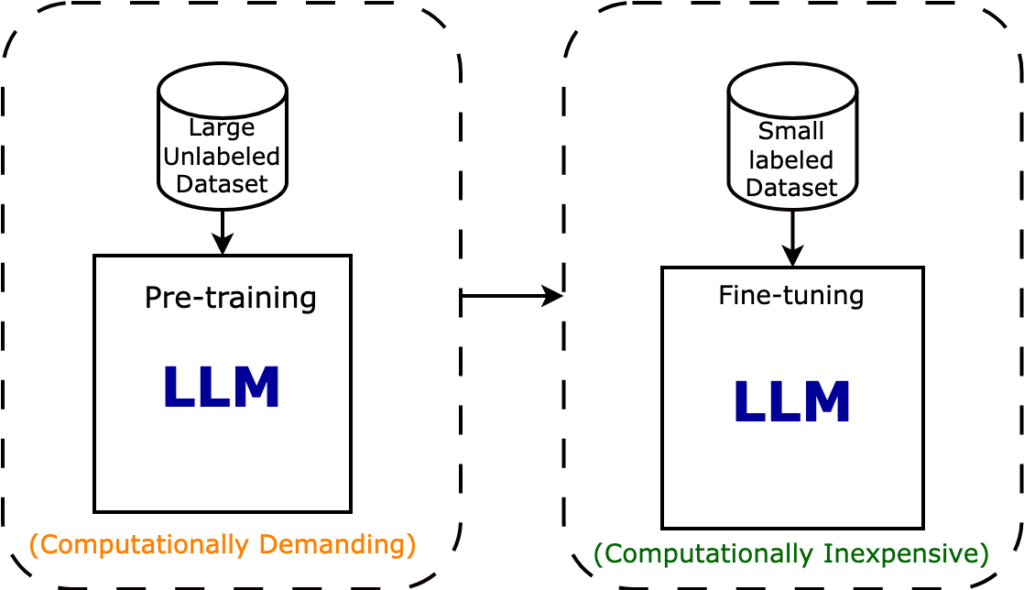
Supervised Fine-tuning: customizing LLMs, by Jose J. Martinez, MantisNLP
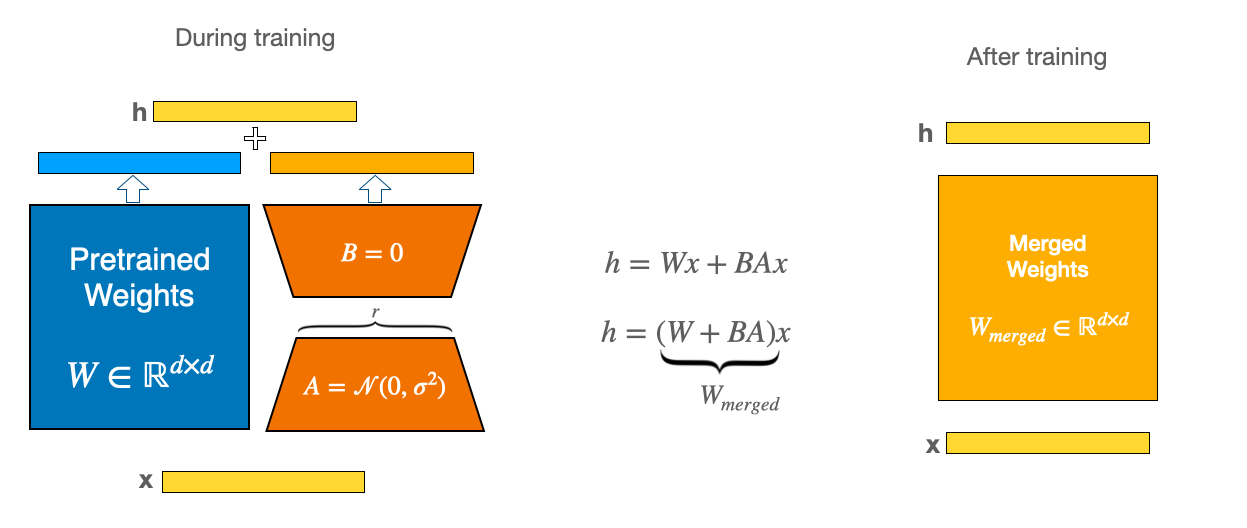
Large Language Model Fine Tuning Techniques

LLM Fine-Tuning: What Works and What Doesn't?, by Gao Dalie (高達烈)

The LLM Triad: Tune, Prompt, Reward - Gradient Flow

Building Domain-Specific LLMs: Examples and Techniques
Complete Guide On Fine-Tuning LLMs using RLHF

The complete guide to LLM fine-tuning - TechTalks

Beginner's Guide to Creating High-Performing Models using Fine-Tuning, RLHF, and RAG

RLHF (Reinforcement Learning From Human Feedback): Overview + Tutorial

Akshit Mehra - Labellerr
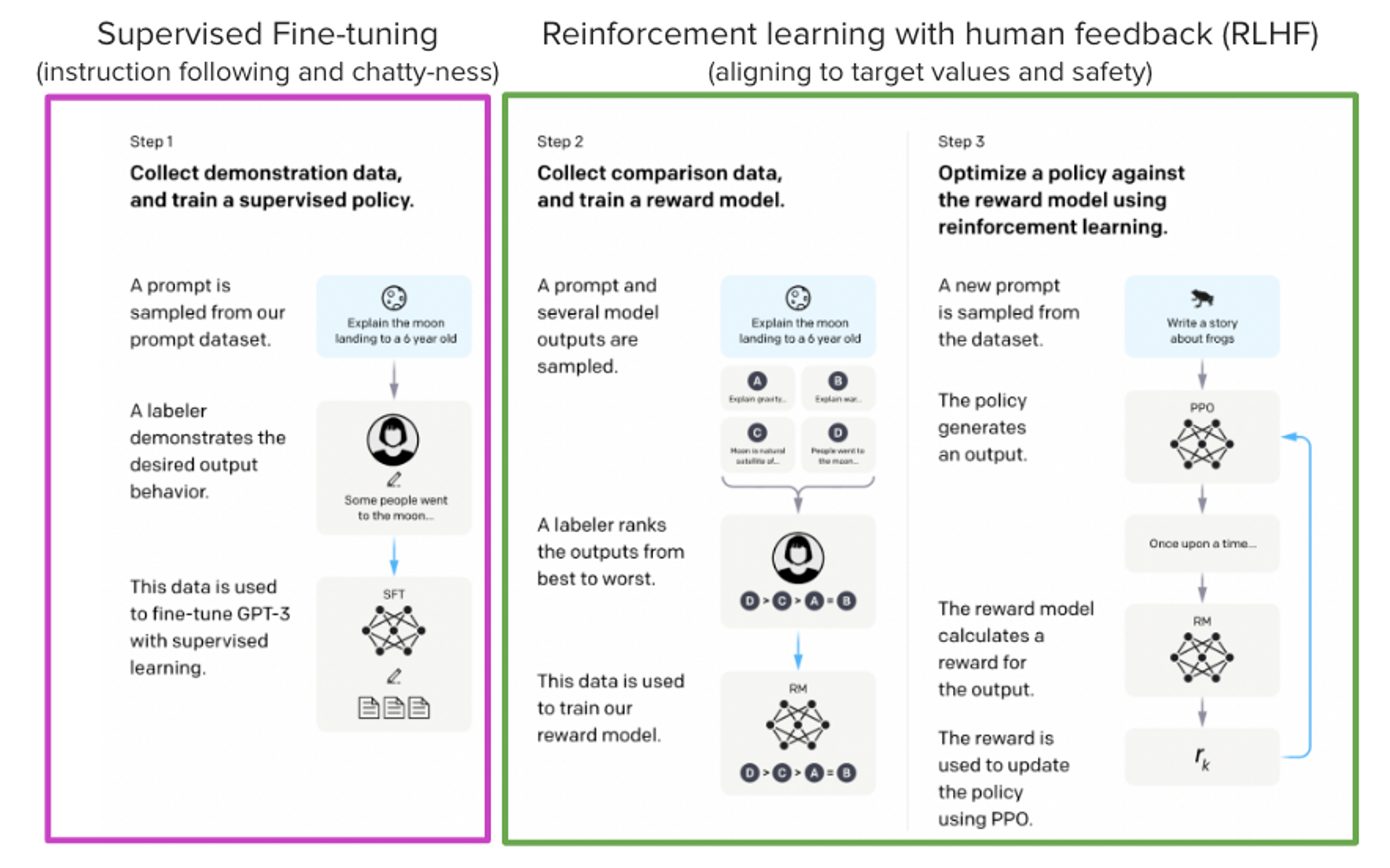
StackLLaMA: A hands-on guide to train LLaMA with RLHF
.png)
A Comprehensive Guide to fine-tuning LLMs using RLHF (Part-1)
Cerebras Announces Fine-Tuning on the Cerebras AI Model Studio
Fine-tuning large language models (LLMs) in 2024
Fine tuning icon gear and screwdriver service Vector Image
Fine-Tuning LLMs With Retrieval Augmented Generation (RAG), by Cobus Greyling
 Carhartt: Storm Defender® Relaxed Fit Midweight Pant (Black
Carhartt: Storm Defender® Relaxed Fit Midweight Pant (Black Mock Neck Sleeveless Sweater – Another Tomorrow
Mock Neck Sleeveless Sweater – Another Tomorrow- Threadbare Petite legging shorts and oversized T-shirt set in gray
 En toalla, Chiquis Rivera vuela la red al mostrarse al natural y
En toalla, Chiquis Rivera vuela la red al mostrarse al natural y Legging Finn 210 Men (2023)
Legging Finn 210 Men (2023) American Breast Care Women's Soft Cup Bra White 44D at
American Breast Care Women's Soft Cup Bra White 44D at
